CI/CD development documentation
Development guides that are specific to CI/CD are listed here.
CI Architecture overview
The following is a simplified diagram of the CI architecture. Some details are left out in order to focus on the main components.
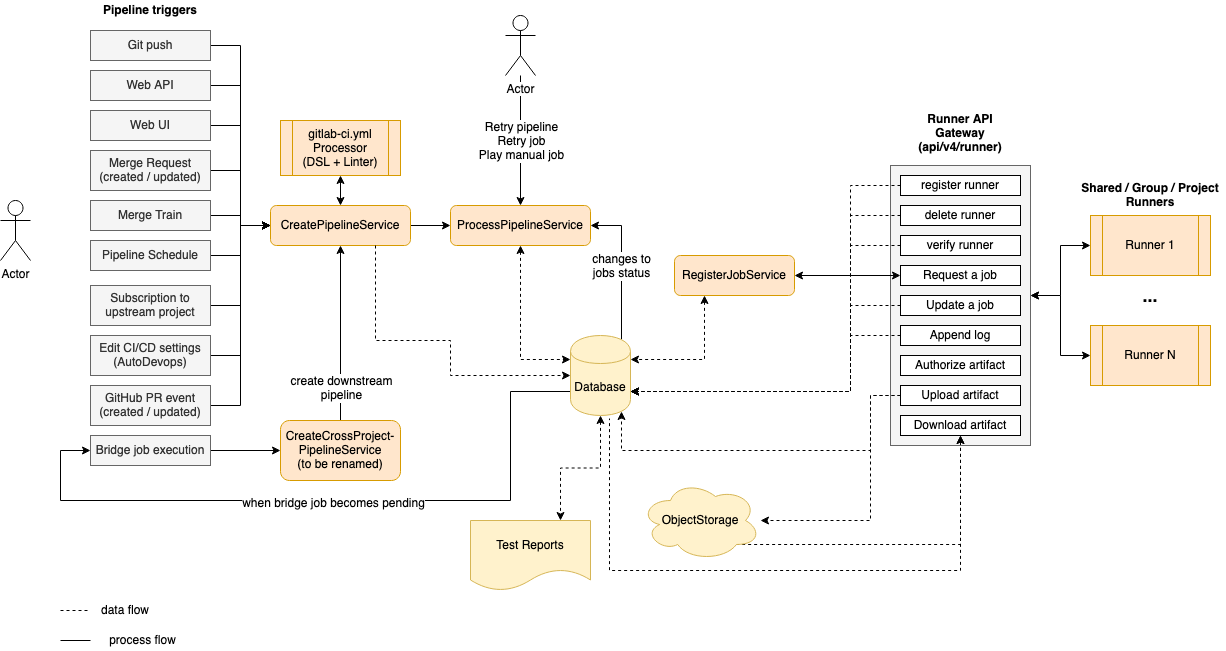
On the left side we have the events that can trigger a pipeline based on various events (triggered by a user or automation):
- A
git pushis the most common event that triggers a pipeline. - The Web API.
- A user clicking the "Run Pipeline" button in the UI.
- When a merge request is created or updated.
- When an MR is added to a Merge Train.
- A scheduled pipeline.
- When project is subscribed to an upstream project.
- When Auto DevOps is enabled.
- When GitHub integration is used with external pull requests.
- When an upstream pipeline contains a bridge job which triggers a downstream pipeline.
Triggering any of these events will invoke the CreatePipelineService
which takes as input event data and the user triggering it, then will attempt to create a pipeline.
The CreatePipelineService relies heavily on the YAML Processor
component, which is responsible for taking in a YAML blob as input and returns the abstract data structure of a
pipeline (including stages and all jobs). This component also validates the structure of the YAML while
processing it, and returns any syntax or semantic errors. The YAML Processor component is where we define
all the keywords available to structure a pipeline.
The CreatePipelineService receives the abstract data structure returned by the YAML Processor,
which then converts it to persisted models (pipeline, stages, jobs, etc.). After that, the pipeline is ready
to be processed. Processing a pipeline means running the jobs in order of execution (stage or DAG)
until either one of the following:
- All expected jobs have been executed.
- Failures interrupt the pipeline execution.
The component that processes a pipeline is ProcessPipelineService,
which is responsible for moving all the pipeline's jobs to a completed state. When a pipeline is created, all its
jobs are initially in created state. This services looks at what jobs in created stage are eligible
to be processed based on the pipeline structure. Then it moves them into the pending state, which means
they can now be picked up by a Runner. After a job has been executed it can complete
successfully or fail. Each status transition for job within a pipeline triggers this service again, which
looks for the next jobs to be transitioned towards completion. While doing that, ProcessPipelineService
updates the status of jobs, stages and the overall pipeline.
On the right side of the diagram we have a list of Runners
connected to the GitLab instance. These can be Shared Runners, Group Runners or Project-specific Runners.
The communication between Runners and the Rails server occurs through a set of API endpoints, grouped as
the Runner API Gateway.
We can register, delete and verify Runners, which also causes read/write queries to the database. After a Runner is connected,
it keeps asking for the next job to execute. This invokes the RegisterJobService
which will pick the next job and assign it to the Runner. At this point the job will transition to a
running state, which again triggers ProcessPipelineService due to the status change.
For more details read Job scheduling).
While a job is being executed, the Runner sends logs back to the server as well any possible artifacts that need to be stored. Also, a job may depend on artifacts from previous jobs in order to run. In this case the Runner will download them using a dedicated API endpoint.
Artifacts are stored in object storage, while metadata is kept in the database. An important example of artifacts is reports (JUnit, SAST, DAST, etc.) which are parsed and rendered in the merge request.
Job status transitions are not all automated. A user may run manual jobs, cancel a pipeline, retry
specific failed jobs or the entire pipeline. Anything that
causes a job to change status will trigger ProcessPipelineService, as it's responsible for
tracking the status of the entire pipeline.
A special type of job is the bridge job which is executed server-side
when transitioning to the pending state. This job is responsible for creating a downstream pipeline, such as
a multi-project or child pipeline. The workflow loop starts again
from the CreatePipelineService every time a downstream pipeline is triggered.
Job scheduling
When a Pipeline is created all its jobs are created at once for all stages, with an initial state of created. This makes it possible to visualize the full content of a pipeline.
A job with the created state won't be seen by the Runner yet. To make it possible to assign a job to a Runner, the job must transition first into the pending state, which can happen if:
- The job is created in the very first stage of the pipeline.
- The job required a manual start and it has been triggered.
- All jobs from the previous stage have completed successfully. In this case we transition all jobs from the next stage to
pending. - The job specifies DAG dependencies using
needs:and all the dependent jobs are completed.
When the Runner is connected, it requests the next pending job to run by polling the server continuously.
NOTE: Note: API endpoints used by the Runner to interact with GitLab are defined in lib/api/runner.rb
After the server receives the request it selects a pending job based on the Ci::RegisterJobService algorithm, then assigns and sends the job to the Runner.
Once all jobs are completed for the current stage, the server "unlocks" all the jobs from the next stage by changing their state to pending. These can now be picked by the scheduling algorithm when the Runner requests new jobs, and continues like this until all stages are completed.
Communication between Runner and GitLab server
Once the Runner is registered using the registration token, the server knows what type of jobs it can execute. This depends on:
- The type of runner it is registered as:
- a shared runner
- a group runner
- a project specific runner
- Any associated tags.
The Runner initiates the communication by requesting jobs to execute with POST /api/v4/jobs/request. Although this polling generally happens every few seconds we leverage caching via HTTP headers to reduce the server-side work load if the job queue doesn't change.
This API endpoint runs Ci::RegisterJobService, which:
- Picks the next job to run from the pool of
pendingjobs - Assigns it to the Runner
- Presents it to the Runner via the API response
Ci::RegisterJobService
There are 3 top level queries that this service uses to gather the majority of the jobs and they are selected based on the level where the Runner is registered to:
- Select jobs for shared Runner (instance level)
- Select jobs for group level Runner
- Select jobs for project Runner
This list of jobs is then filtered further by matching tags between job and Runner tags.
NOTE: Note: If a job contains tags, the Runner will not pick the job if it does not match all the tags. The Runner may have more tags than defined for the job, but not vice-versa.
Finally if the Runner can only pick jobs that are tagged, all untagged jobs are filtered out.
At this point we loop through remaining pending jobs and we try to assign the first job that the Runner "can pick" based on additional policies. For example, Runners marked as protected can only pick jobs that run against protected branches (such as production deployments).
As we increase the number of Runners in the pool we also increase the chances of conflicts which would arise if assigning the same job to different Runners. To prevent that we gracefully rescue conflict errors and assign the next job in the list.